国工数据大脑之残差检验在回归分析中的应用
2022-02-16 10:26:31
1117
业务背景
在现代化企业管理中,利用数据分析进行决策支持已成为重要手段,其中包括:过程控制、产能预测、市场决策等等。
在各类业务场景中如何用数字直观地描述指标与指标之间的相关性是一个重要命题,该类业务大多基于回归分析法,回归分析法通过对过去的数据进行采样来构建回归模型,从而为决策和行动提供依据和建议。当回归模型拟合不正确,会误导企业决策的方向,浪费大量人力、物力、财力,给企业造成巨大的损失。因此,对回归模型进行诊断是不可或缺的步骤。即判断回归模型是否正确、理想?换句话说,模型是否很好的提取了样本的规律信息。国工智能MAI平台提供了基于残差检验进行回归模型评估的科学算法。
残差检验的内容
经典且理想的回归模型的前提条件是:1.随机误差项各项之间无序列相关;2.随机误差项服从正态分布;3.随机误差项方差都相同或是固定的常数。(在实际应用中,随机误差项用残差来代替)
满足上述三个假设条件说明回归模型是理想的。残差是样本值(蓝点)与回归直线(红线)上的值(又称回归拟合值)之间的差,红线可由数据大脑拟合回归算法得出,具体见下图。残差检验即检查经过回归拟合后得到的残差是否满足上述三个条件。如果违背了上述其中之一的假设条件,就不是经典的线性回归模型,这样的模型用普通最小二乘法来估计往往失效,最后拟合出来的模型往往是有误的,预测的效果也大打折扣。
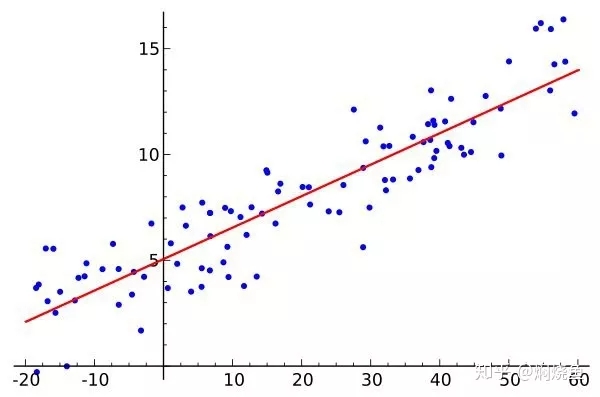
图1
(一)条件1:随机误差项各项之间无序列相关含义序列相关即对于不同的样本数据,其残差之间存在某种相关性,以正相关为例,可以简单理解为如果前一个残差大于0,那么后一个残差大于0的概率较大;而序列不相关是残差之间互不影响,毫无规律,前一个残差对下一个残差的预测没有帮助。如下所示:
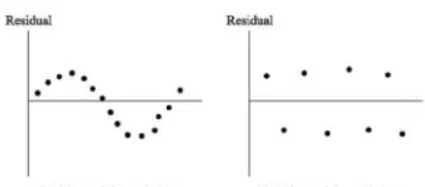
图2 序列正相关
图3 序列不相关
(二)条件2:随机误差项服从正态分布含义
只要回归方程拟合的足够理想,即把所有影响因变量的因素都找对了,找齐了,那么剩下回归拟合值和样本点之间的各个误差项就是服从正态分布的了。对于正态分布,我们只需要知道三件事,1.它长什么样的,就是下图;2.它的两个参数,平均数和标准差;3.对于这个图的解释是什么,也就是样本数据集中在平均数(下图红线的位置)周围,且在总体上占到大多数(如图中绿方框所示,落在绿方框中的样本数据占很大的比例)。
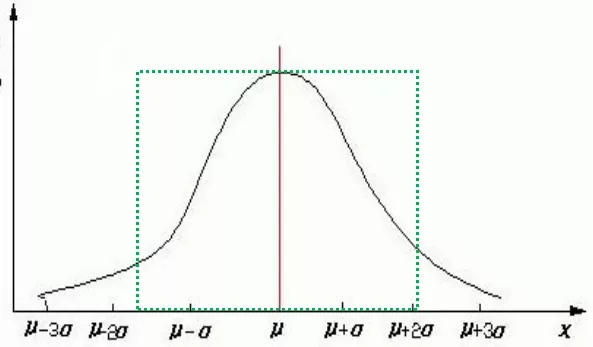
图4
(三)条件3:随机误差项方差都相同或是固定的常数含义(简称同方差)举个例子,假设我们采集到某个菜园大棚内一天内温度和二氧化碳浓度的数据。研究温度(X)对二氧化碳浓度(Y)的影响。无论温度越来越高/低,还是二氧化碳浓度越来越低/高,误差项都不会随之变化而变化,因为各个误差项之间的方差固定。方差反映的是数据的波动程度,方差不变,数据就保持原来的波动程度。
适用范围
所有线性回归模型。
应用场景
化工、酿造等装置性行业的过程控制,往往是多变量共同作用。为了做好过程控制,实现“以因素管理结果",我们运用回归分析的统计技术寻找规律,并用于生产过程控制。例如,啤酒酿造过程中成品啤酒的泡特性(秒),是直接关系到啤酒口感的技术要求。技术和经验表明中间产物的总氮含量X对于需要满足的泡沫时间Y (秒)有影响。数据如下:
表1
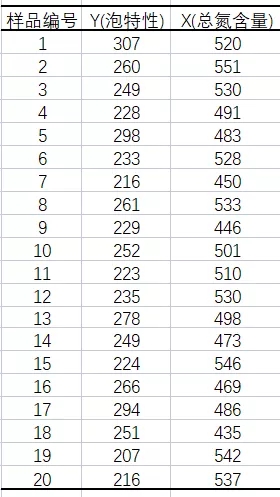
Y=-5406.801+46.51*X
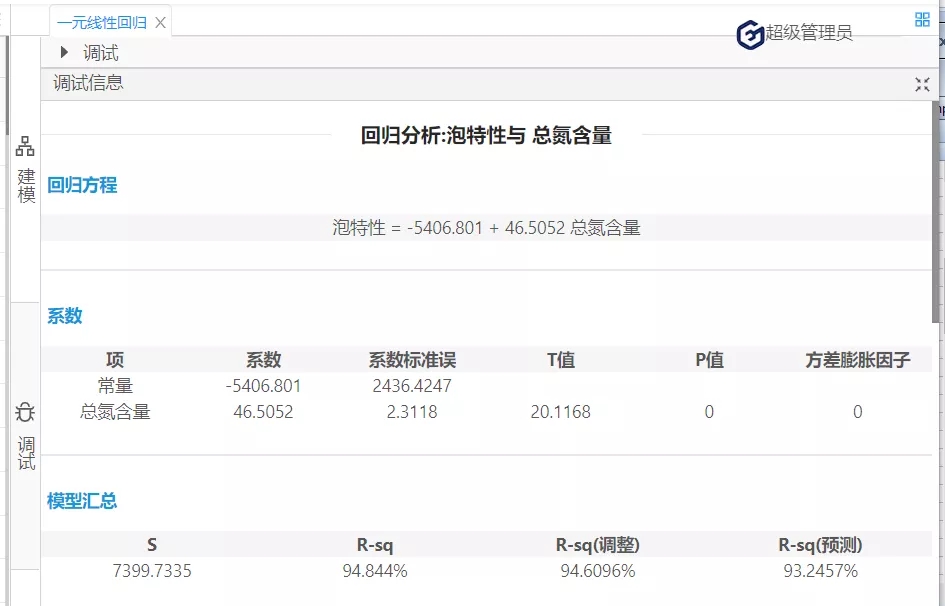
图5
由图5可知,模型已经通过了统计意义的检验。(具体见国工数据大脑之多元线性回归在化学研发成本的预测一文)其次,在此基础上,进一步使用数据大脑平台的残差检验算法判断回归模型的理想度。实现残差检验第一个方面:序列相关性的检验。(原假设是:不存在序列自相关。)打开国工数据大脑平台。从数据大脑中的组件面板搜索残差检验组件,拖到到工作面板,配置数据及参数。在诊断方法下拉列表选择:Correlogram-Q-statistics;滞后阶数选择:12。如图6:
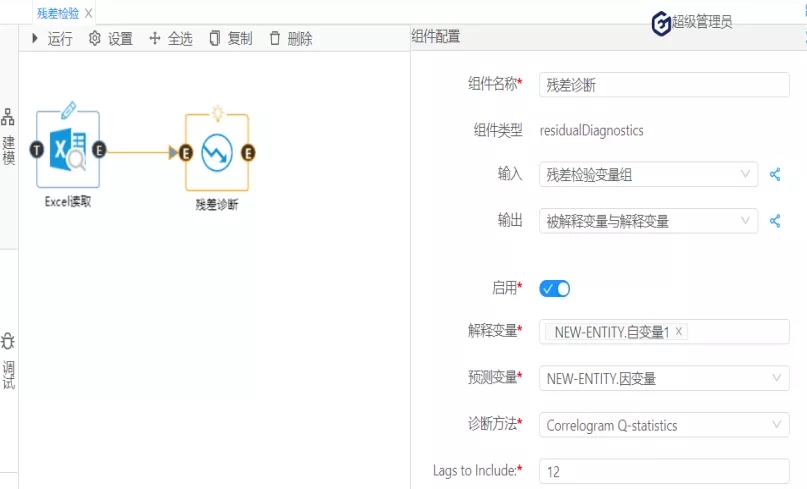
图6
运行结果:
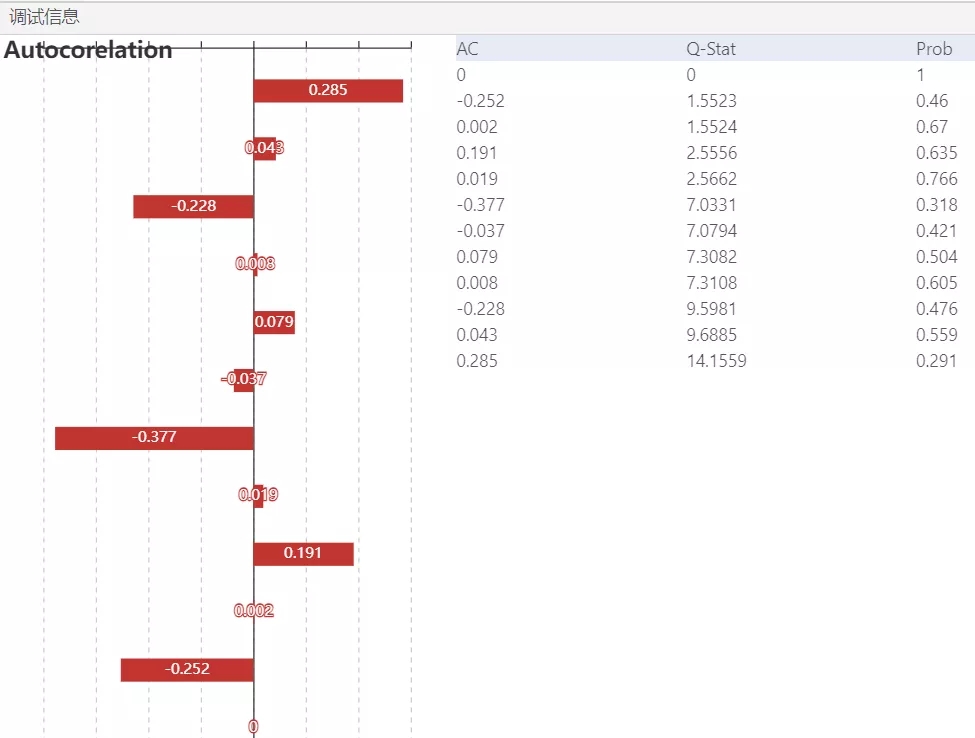
图 7
根据图7可知,无论滞后阶数为几,其p值都大于0.1的显著性水平,接受原假设,残差序列不存在序列相关。
接下来,进行残差检验的第二个方面:残差序列正态性检验。(原假设:序列服从正态分布)在诊断方法下拉列表选择:Histigram-Normality-Test;如图3:
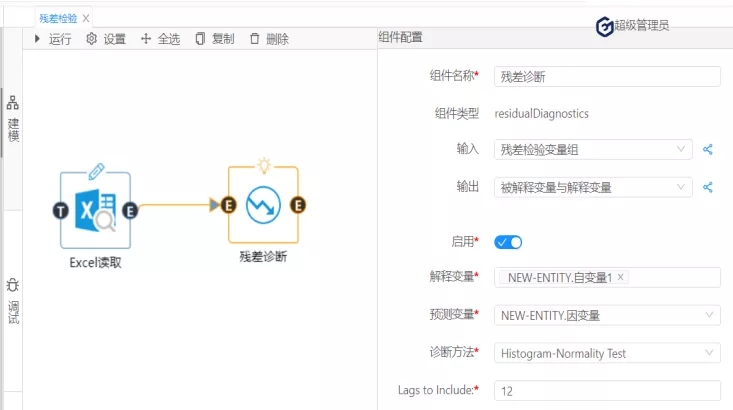
图 8
运行结果:
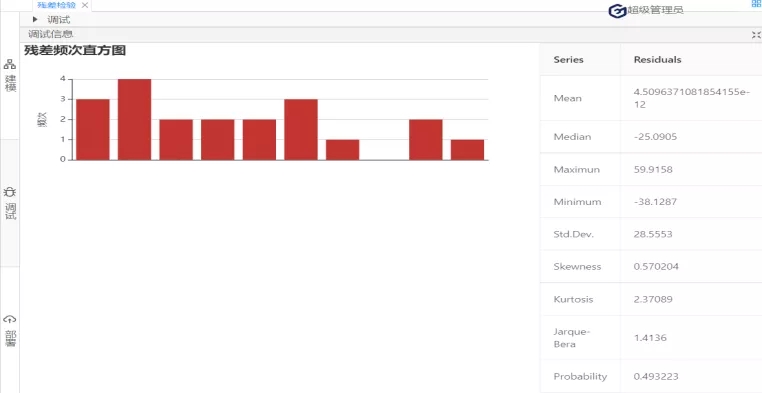
图 9
根据图9可知,Jarque-Bera(JB)统计量的值为1.4136,它服从自由度为2的卡方分布,在0.1的显著性水平下,其临界值=4.605,故JB统计量<临界值,接受原假设,该残差序列服从正态分布。最后,进行残差检验的第三个方面:检验方差是否相同。(原假设:序列方差相等)在诊断方法下拉列表选择:Heteroskedasticity-Tests(怀特检验);如图10:
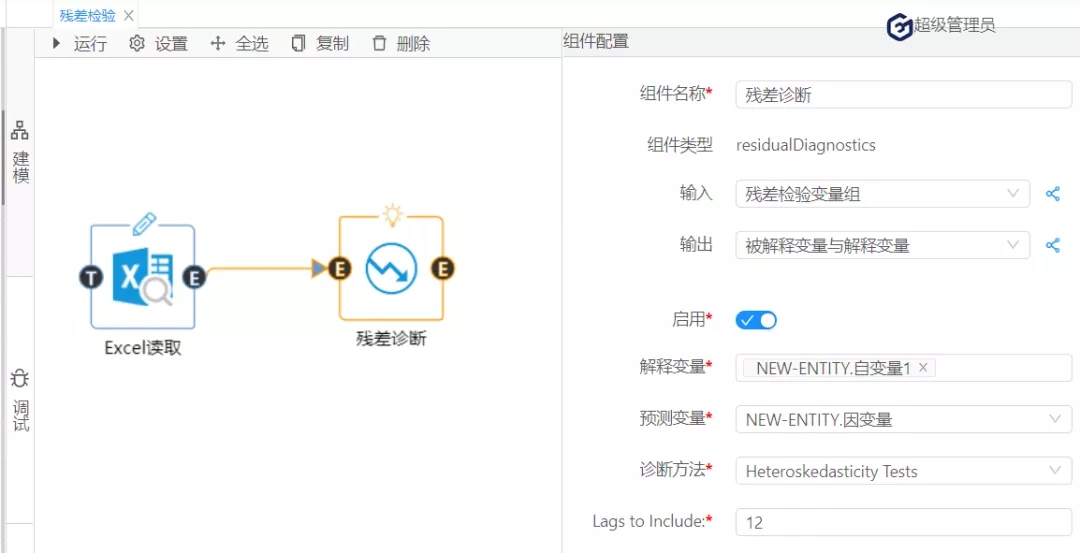
图10
运行结果:

图11
根据图11可知,怀特检验统计量的值为1.052,它也服从自由度为2的卡方分布,在0.1的显著性水平下,其临界值=4.605,怀特检验统计量值<临界值,接受原假设,该残差序列存在方差相等的情况。
综上,在啤酒的泡特性与总氮含量的一元线性回归模型中,该残差序列不存在序列相关,服从正态分布,且方差相同,上述的三个条件都满足,说明回归模型拟合不错且准确,可使用该模型进行预测。
在下一批生产中,若X(总氮含量)=130,则Y(泡特性)的预测值=-5406.801+46.51*130=639.3(秒),以此类推,能够预测到未来若干次生产中的成品啤酒的泡特性,可通过降低总氮含量等措施控制啤酒的泡特性,从而实现生产控制,实现效益最大化的目标。(具体预测及回归模型含义国工数据大脑多元线性回归在化学研发成本的预测一文)
最新文章

智能光谱分析驱动氯碱行业技术革新:山东企业的创新实践与产业价值
284
2025-07-14
在氯碱化工复杂的生产体系中,关键指标的精准检测如同工业交响乐的指挥系统,直接影响产品质量稳定性、生产安全阈值及成本控制精度。作为全国化工产业重镇,山东企业依托深厚的产业积淀与持续的技术创新,在氯碱行业在
培训赋能AI化工升级,客户价值驱动产业创新
297
2025-07-14
夏日的烟台,海风送爽。在第十届烟台国工智能科技有限公司AI研究院“AI课题文献综述分享茶歇会”上,一场聚焦“人工智能与化工领域深度融合”的智慧盛宴成功举办。

洞见化工“热”力,驾驭AI“智”能
279
2025-07-04
——从热力学秩序到工业智能,国工AI赋能化工研发与生产的底层突破 开篇 茶香氤氲,智慧碰撞 近日,第九届烟台国工智能科技有限公司AI研究院&l

智能光谱分析驱动氯碱行业技术革新:山东企业的创新实践与产业价值
280
2025-07-04
在氯碱化工复杂的生产体系中,关键指标的精准检测如同工业交响乐的指挥系统,直接影响产品质量稳定性、生产安全阈值及成本控制精度。作为全国化工产业重镇,山东企业依托深厚的产业积淀与持续的技术创新,在氯碱行业在线检测领域构建了从技术研发

探索AI赋能高分子配方设计新未来!
497
2025-06-27
6月9日,第八届烟台国工智能科技有限公司AI研究院“AI课题文献综述分享茶歇会”成功举办。本次会议聚焦“基于遗传算法的高分子配方设计方法”,通过前沿技术分享与案例解析,展现了国工智能在AI+材


烟台国工智能科技有限公司是一家提供智能制造解决方案及落地服务的高新技术企业,为制造业(化工|医药|材料|食品)提供以人工智能为核心的软件:MES,mes系统,lims,实验室管理平台,scada,数字孪生平台,人工智能研发,研发管理平台,智能光谱分析系统,咨询热线:400-660-1686。
加入我们










